A common requirement of (collaborative) modeling work is the ability to compare one version of an RDF model (or file) with a previous version. Doing this with conventional mechanisms such as file diff tools is usually insufficient, because the serialization of RDF files may change with each iteration.
If you want to use text-based diff tools such as those built-into the Eclipse context menu (right-click on a file in the Project Explorer and use Compare with) then you should save your file in Turtle, as TopBraid produces a very reliable Turtle serialization.
In addition to the text-based comparison, TopBraid Composer also introduces a structural comparison tool that is fully aware of RDF syntax, as described in the following sections.
If you want to compare the currently open model with some other file in your workspace, go to Model > Compare current RDF model with.... This will ask you to select the other (old) version of the file. After you have selected the file, TopBraid's diff engine will execute and create and open a diff file which you can then browse to analyze the differences.
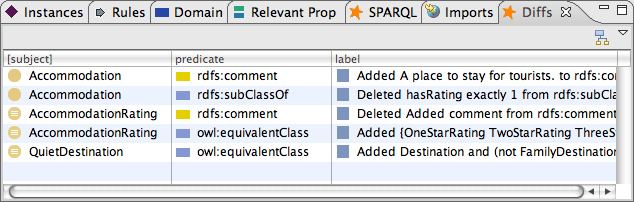
The most common way to display the results is to use Run SPARQL query from SPIN template... which is both in the main tool bar and main menu. Select diff:ShowAllDiffs to get a list of changes such as the one shown below. Click on any item to navigate to the resource that has changed.
Note that you can also use this diff tool from SPARQLMotion, using the
sml:Diff module.
The result of the diff algorithm is a collection of instances of a dedicated diff ontology (http://topbraid.org/diff). You can typically find this diff ontology in your workspace under the TBC folder of the default project.
The class diff:Diff has subclasses for the two kinds of diffs that are
supported:
Each instance of these classes represents a single change. Blank nodes are treated differently, because the identifiers of blank nodes change with each serialization. Instead of attempting a structural comparison of blank nodes, our algorithm simply compares the string rendering, which works fine for the most common cases such as OWL restrictions.
Details of each diff object are stored in properties such as rdf:predicate
and these details can be queried or further processed using a whole range of
RDF-based tools, in particular SPARQL.
TopBraid's Diff engine is entirely declarative and can be modified or extended
to get customized output. The various diff classes have SPARQL queries attached
to them via diff:rule. These queries are called by the engine to create
the instances of this class. The GRAPH keyword of SPARQL is used
to query the old graph versus the new graph. If you want to add your own kinds
of diff outputs, then simply add such diff:rules.
The second step of the Diff engine is to call all spin:rules
for the constructed instances of the diff classes. These rules can be used
to post-process the raw output from the first step, e.g. to create human-readable
labels. The same mechanism can be used to create higher-level diff objects from
the lower-level triple change objects.
You can modify the diff.ttl file in your workspace to adjust the behavior of the
diff engine for your needs.