An example spreadsheet can be found here for creating a new ontology. To convert such a tab-separated text file into a new ontology, right-click on a target folder and select Import > TopBraid Composer > Import Tab-Delimited Spreadsheet File. This will take you to the following wizard page:
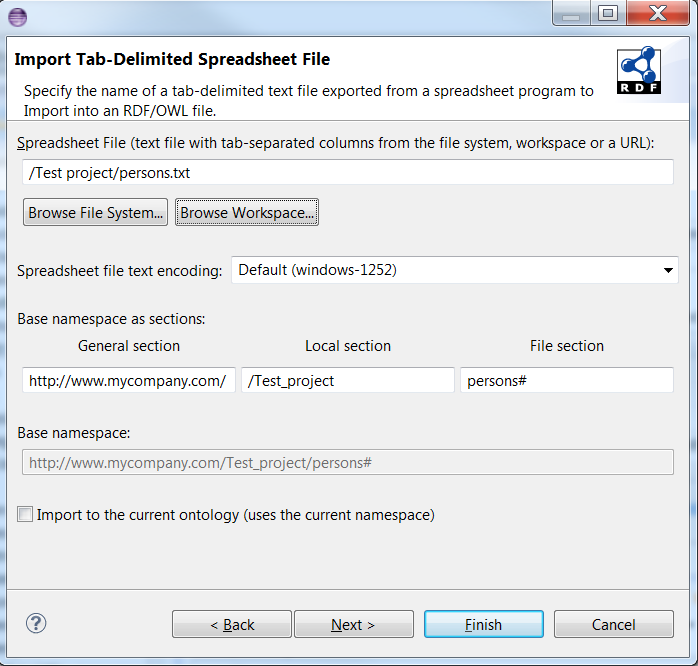
On this page you can specify the spreadsheet file, the target namespace and whether you want to import the file to the current ontology or not:
- Spreadsheet File: The source file could either come from the file system, the workspace or from the Internet.
- Base namespace as sections: The base namespace is constructed by joining three sections. These sections are initialized from a stored value, target folder or the name of the spreadsheet file, respectively. However, you can edit them for your own purpose. They are described as follows:
- General section: This section contains the saved part of the namespace. In this example, it is the value http://www.mycompany.com. If you modify this section, the change is saved, and the general section will be initialized with this stored value next time. However, if the current project name itself is a URI, then the project name is used to specify the general section instead. For example, if the path of the target folder is /www.examples.com/page1/, then the general section becomes http://www.examples.com.
- Local section: This section is initialized with the path of the target folder. In the example, a right-click was made on the folder /Tests/Examples, and this folder is used for the local section of the namespace.
- File section: The file name of the spreadsheet file is used to initialize the file section. In the example, the spreadsheet file path is /Tests/spreadsheets/persons.txt. The file name persons.txt is taken and converted to persons#, which is a valid ending for a namespace.
- Base namespace: This shows a preview of the union of the general, local and file sections of the namespace.
- Import to the current ontology: By using this checkbox, you can choose to import the spreadsheet to the currently selected ontology.
If you click Next, then you get to the second page, where you can set the properties for importing the spreadsheet:
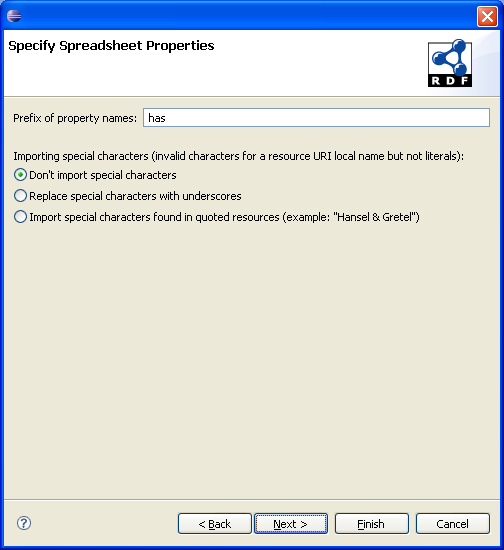
In this page, you can specify the prefix to be used in property names. In this example, the property prefix is has, which will be used as a prefix for all properties, that will be imported. Also, you can specify the policy in importing special characters. In this context, the special characters are invalid characters that are not typically found in the local name of a resource URI. This excludes the characters in literals. By default, they are not imported. They can be replaced by underscores or they can be imported if the resource is quoted in the spreadsheet.
All the data in this page is also saved, so you can use them next time.
If you click Next, then you are at the last page of the wizard, where you can preview and modify the data about spreadsheet columns.
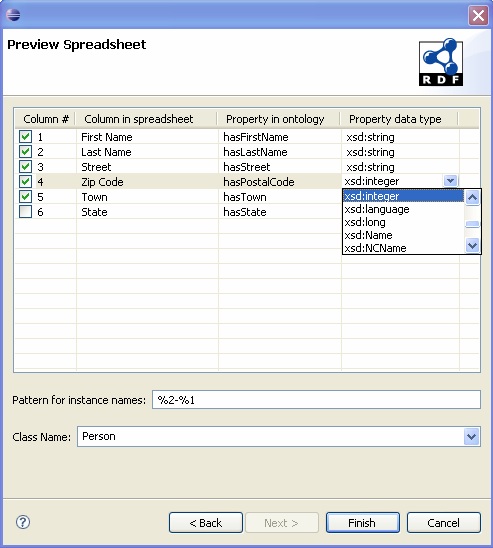
The above page consists of these components:
- Spreadsheet column table: This table provides a preview of the properties that will be
imported. You can select which columns to be imported, modify the column property name to be used,
and property data type, which can be selected from the combo-box. In this example, all properties
have the prefix has, which was defined in the earlier page. Column #6, State is unchecked,
so it won't be imported. The property name for Zip Code is changed
to hasPostalCode and its data type is assigned
xsd:integer.
As an additional note, if there is an ontology already open with the same namespace, and if the properties from this table already exist in the ontology, then the property data types in the table will automatically switch to the data types of the properties from the ontology. Thus, data types could be picked up from an existing ontology, even though in this case, the spreadsheet is not imported to that ontology.
- Pattern for instance names: This defines the pattern that instance names are created with, when they are imported. In this example, it is %2-%1, which means that an instance name would look like [name of a column #2 item]-[name of a column #1 item]. If there are items John in column #1, and Doe in column #2 in the same row, then this would be created as Doe-John.
- Class name: This contains the class name that will hold the imported data.
After you click Finish, the resulting file will contain exactly one OWL class, with one datatype property for each selected column in the file as specified in the preview table. The property names will be derived from the preview table. Each row in the spreadsheet will be converted into an instance of the specified class. The name of each instance is created in the form of the specified pattern.
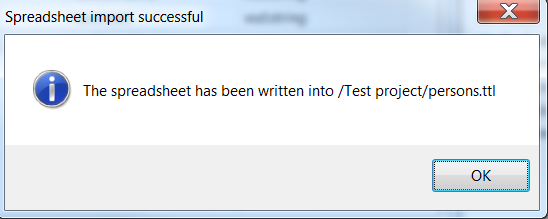
If the import was successful, a message will notify you about the location of the resulting file:
This file can then be opened and will look as shown below. The RDF file can be downloaded from here. The first image gives an overview of the class that is created, and the second image shows an instance in this ontology:
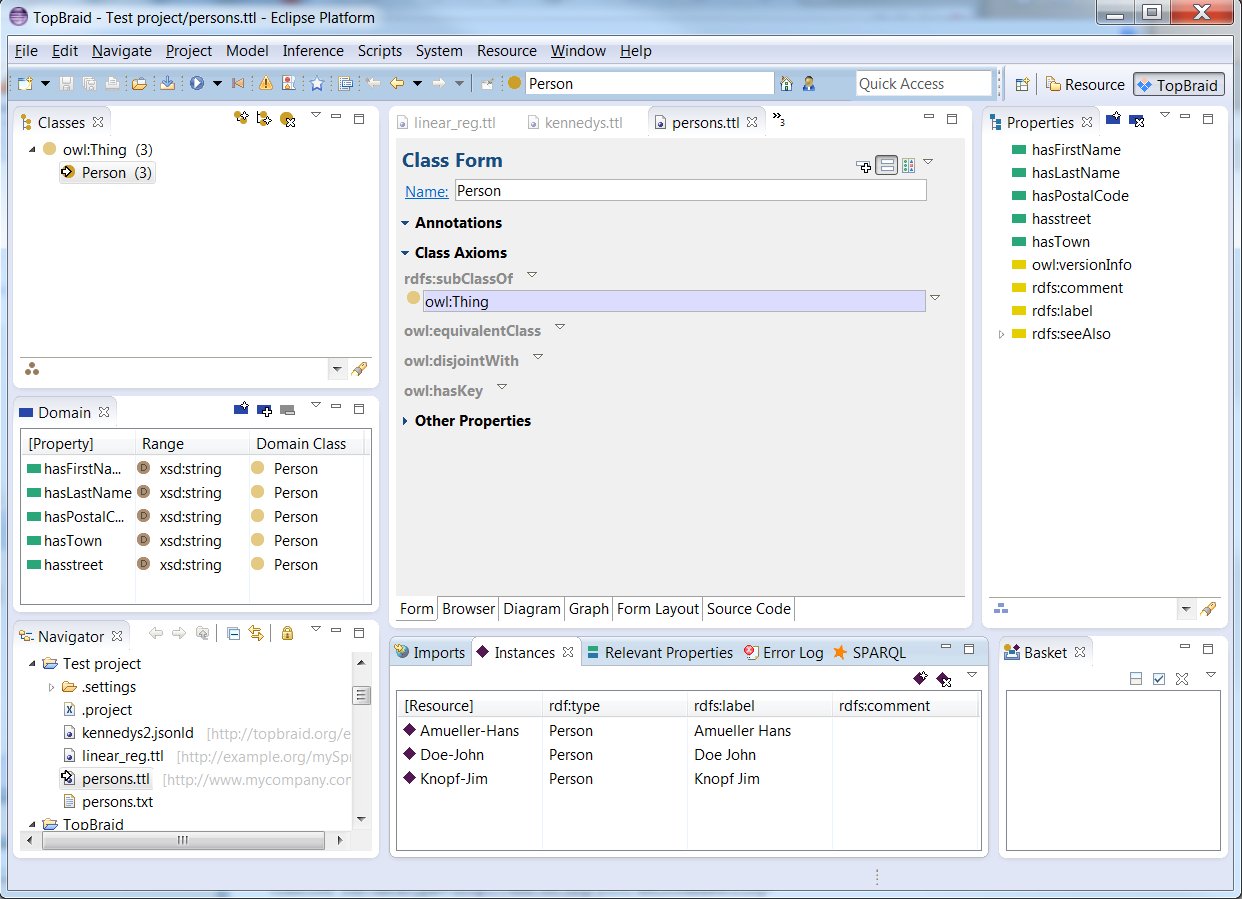
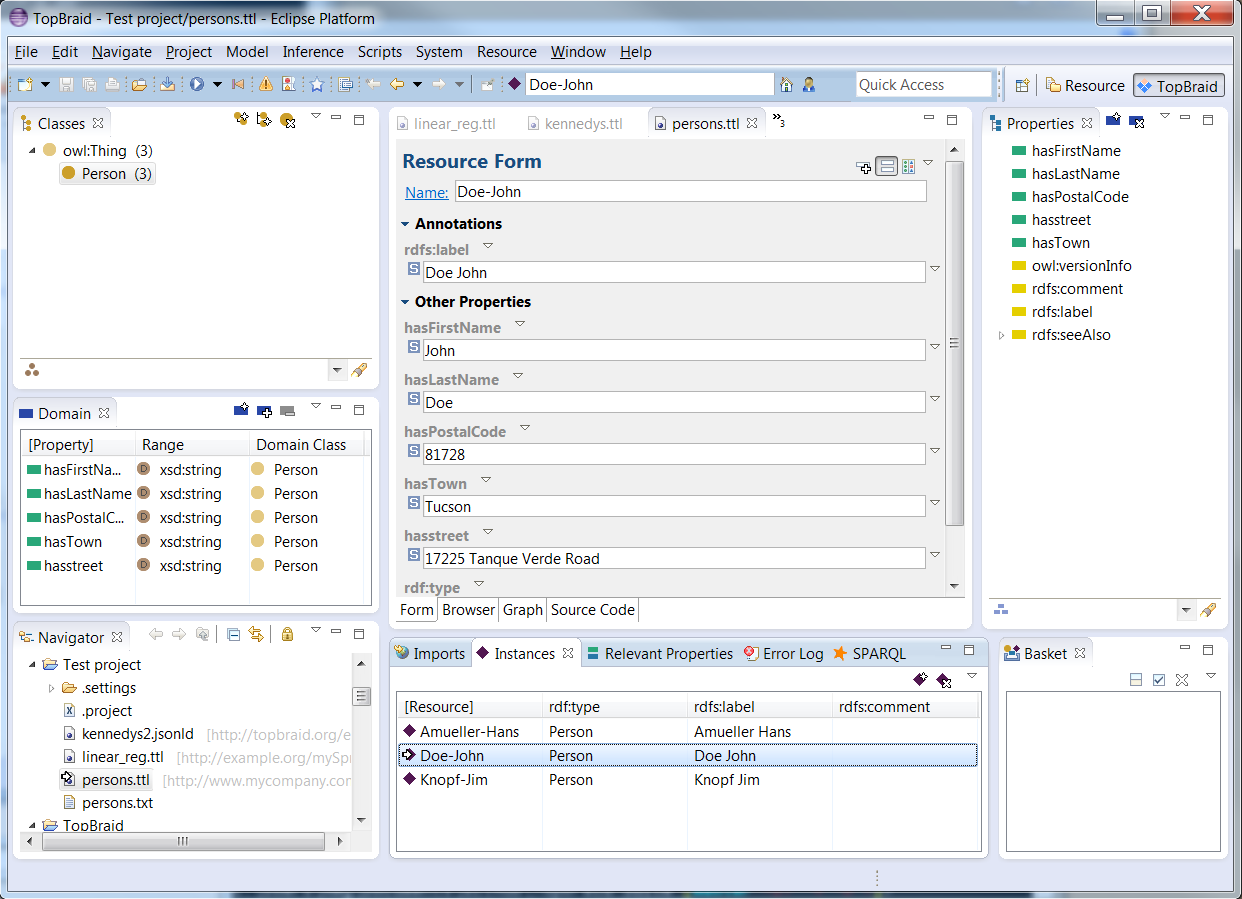
The Spreadsheet import is typically used as a first step only. In many cases you may want to use the Extract class refactoring to split the resulting class into multiple classes.
This case differs from creating a new ontology from the spreadsheet. In this case, the first column name defines the target class name in the current ontology. The first column items contain the instance names, that are the instances of the target class name. The other column names are the properties and the other column items contain the object data. Thus, the first column items are subjects, the other column names are predicates, the other column items are objects of the statements that are created.
In this regard, the spreadsheet should be similar to the Instances View table for a proper import. Except for the class name, all the items in the spreadsheet are mapped or created depending on if they are found or not in the ontology. The class name defined in the spreadsheet must exist in the ontology, so it is strongly advised to walk through all pages of the wizard, before doing the import.
The spreadsheet importer supports namespace prefixes in importing to the currently selected ontology. It also prepends an underscore character for any resource that doesn't begin with a letter to ensure proper import.
An example spreadsheet can be found here to import to the currently selected ontology. To import such a tab-separated text file into the currently selected ontology, first open the target ontology. In this example, this ontology is used, which doesn't yet contain any data from the spreadsheet. Then, select the same wizard, Import > TopBraid Composer > Import Tab-Delimited Spreadsheet File as in the previous section. This will take you to the following wizard page:
The main difference in this page is that Import to the current ontology button is checked, which means that the spreadsheet will be imported to the currently selected ontology and use its namespace. Thus, the namespace is not shown in sections in this case, and the namespace of the current ontology is used.
If you click Next, then you get to the second page:
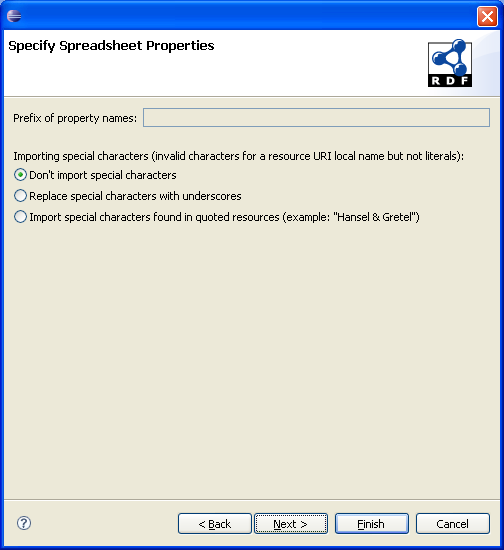
In this page, the difference is that the prefix for property names is not used to ensure proper mapping between the column names and existing properties.
If you click Next, then you are at the last page of the wizard, which has some differences for importing into the current ontology.
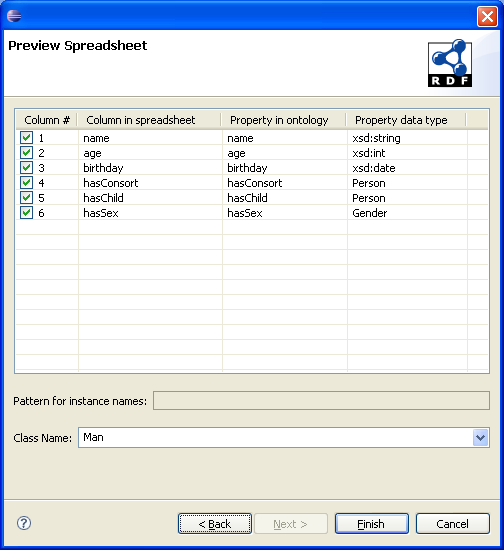
In this case, the first column is not shown in the preview, because it contains the subjects. If the properties are in the ontology, then their data types are automatically assigned from the ontology. The difference in this case is that the data types are fixed, i.e. the wizard prevents from changing the data type of an existing property. However, property names can still be changed.
This page also prevents a pattern to be defined for instance names, because the first column items are used as instance names. Class name must exist in the current ontology, so an error will be given if it doesn't exist.
After you click Finish, the spreadsheet items are imported as statements into the ontology as described above. A log file is written to the same folder as the ontology. The import can be undoable with one click. The example ontology would look like the following after the spreadsheet import:
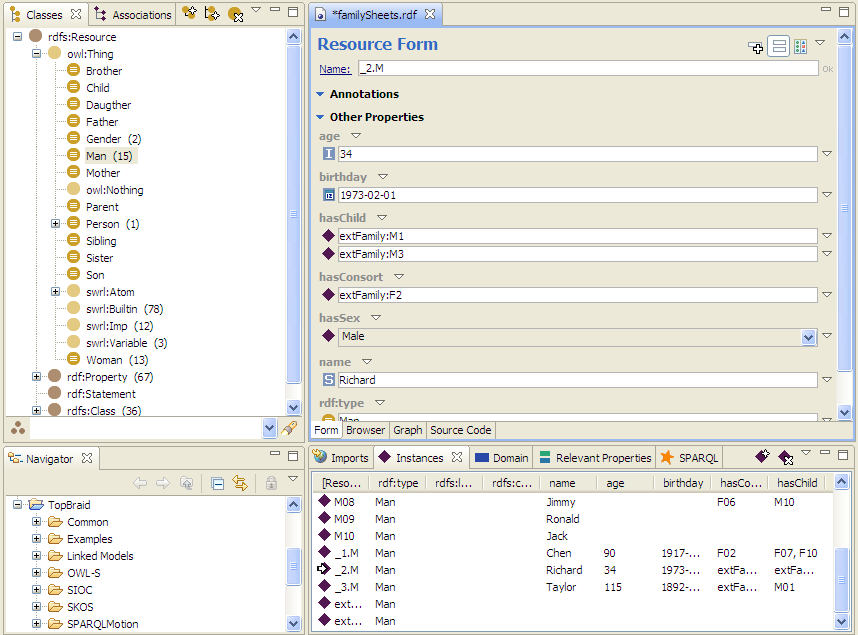
You can see in the above ontology that, an underscore is prepended during import to the original instance name 2.M, which is imported as _2.M. It can also be seen that the resources with namespace prefixes such as extFamily:M1 was imported correctly given that the namespace prefix extFamily is already defined in the ontology.