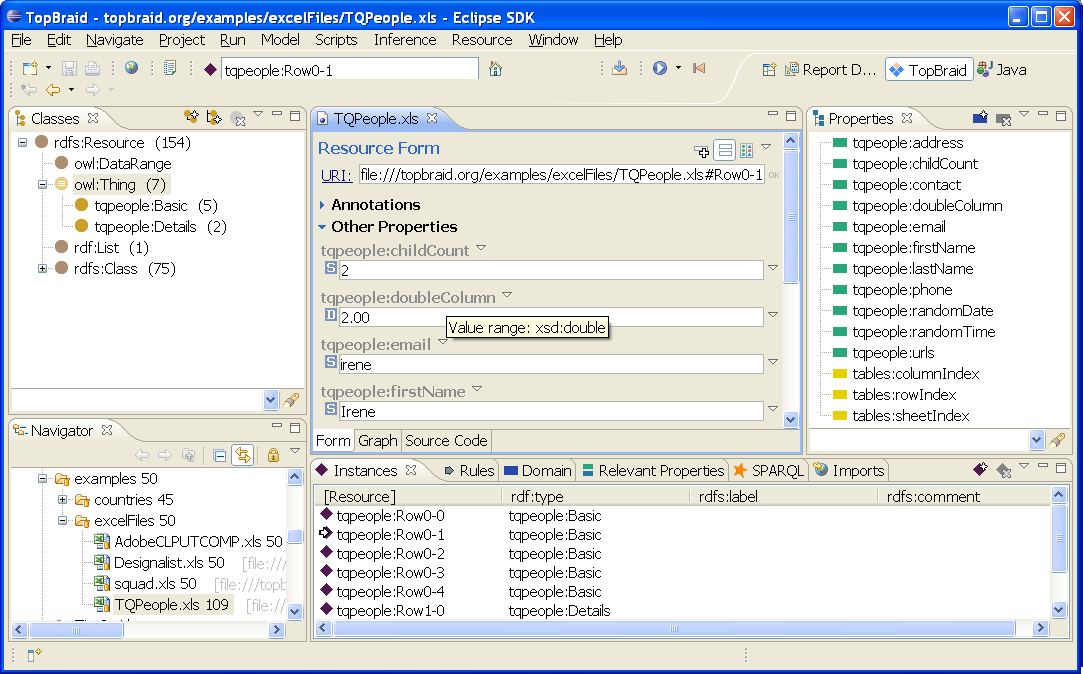
Semantic Tables is a technology from TopQuadrant for mapping arbitrary Table documents to RDF. Semantic Tables can be used to convert Table files to RDF so that you can run SPARQL queries etc on them. You can also manipulate the resulting OWL model and then save it back to the original format.
The following example screenshot shows how a simple example Table file has been rendered into OWL using TopBraid:
Semantic Tables is based on a small ontology that defines three annotation properties to enable round-tripping between the Table file and OWL. It introduces tables:columnIndex, tables:rowIndex, and tables:sheetIndex that are used to define the mapping. When a Table file is opened with TopBraid, it will apply the following mapping strategy:
Table files can be automatically imported into TopBraid Composer by opening the desired file (as if they were a regular ontology file).
Currently supported files:
| File Format | Expected File Extension |
|---|---|
| Microsoft's Excel | xls |
| Comma Separated Values | csv |
| Tab Separated Values | tsv |
Any workspace file ending with .xls, .xlsx, .csv, and .tsv can be opened directly with TopBraid. The system will automatically convert its contents into Semantic Tables format. The table file can also be imported into other OWL ontologies using the Imports View.
Note: When importing .csv or .tsv files, the system will use the platform's default character encoding. If you want to use something else, e.g. UTF-8, then you need to specify a different encoding for the file in your Eclipse workspace prior to running the import. To do that, right-click on the file in the Project Explorer, select Properties and pick a custom encoding in the drop down box.
Reusing existing schemas with .semtables files
By default the system will create a completely new schema (classes and properties)
for each tables file. However, in many cases it is desirable to reuse the same
schema for multiple instance files, for example to reuse SPARQL mappings defined on
those existing classes and properties. This can be achieved by means of .semtables
files. These are metadata files that are placed in the workspace together with the tables
files themselves. .semtables files contain information about which other graphs (base URIs)
need to be present when the table file is loaded.
When a spreadsheet is loaded, the system will first try to find a file with the same name
plus the suffix .semtables. For example, if you have a file example.tsv
then the system will search for a file example.tsv.semtables in the same folder.
If this is not present, the system will search for a file default.semtables in the
same folder, and finally walk up the parent folder structure for any other default.semtables
file.
The easiest way to create such .semtables files is to:
.semtables file has been found that would point to an existing
ontology, the system will ask you whether you want to select an ontology manually.
Click Yes to continue..semtables file, either for this specific file,
the folder or the project, so that in the future you don't have to select the
ontology file again.
Note that if a column property defines a different range than xsd:string,
the importer will create a typed literal. For example if a spreadsheet already contains
well-formed xsd:date strings, then the schema may define xsd:date
as the rdfs:range of the matching property. A common, and more powerful
alternative to this datatype resolution is to use SPIN (especially SPINMap)
to define mappings from the source schema into a target schema.
In order to prepare for the reuse of a schema file, you could simply load a spreadsheet
without a .semtables file, delete all instances, adjust the base URI and save
the file (now consisting only of classes and properties).
Alternatively, if you already have a schema file, you could create a new file that imports
the schema plus the http://topbraid.org/tables namespace. In this file,
add the property tables:sheetIndex to the main class, with value 0.
Then make sure that each column property has the main class as its rdfs:domain.
Finally, give each column property a tables:colIndex, starting with 0.
Using and saving the ontology back to the Table File.
TopBraid Composer allows the editing of Table Files as if they were ontologies. Note that there is no traditional ontology file created, such as .rdf or .ttl.
Columns (converted into Properties) and Rows (converted into Instances) are specific for each Sheet (converted into Classes). Adding instances to classes will implicate in creating new rows in the original Table File.
Select Save to save the ontology back to the Table File.
If classes or properties were added to this structure, they will not be converted back into new Sheets and Columns, unless the sheetIndex, columnIndex, and rowIndex are correctly used. We do not recommend, however, that users modify the ontology in this manner.