TopBraid provides several ways to support data integration. In all cases, the first step is to render all datasets to be integrated as RDF. Once these datasets are available as RDF, there are several ways to merge them.
Many data sources are already available as RDF, and are published in one of the standard RDF serializations (Turtle, NTriples, RDF/XML). When data is available in one of these formats, there is no need to turn it into RDF; it can be used directly in TopBraid Composer simply by dragging and dropping the file into a project in the TopBraid workspace.
Many other forms of data (XML, Spreadsheets, etc.) can be converted into RDF in a one-time conversion step. See Importing External Information for details. These create RDF files with a snapshot of the data as it was in the input dataset at time of conversion.
For relational databases, they can be rendered as RDF dynamically, effectively creating a proxy file to the data in the database (see Import Relational Databases with D2RQ). This proxy stands in for the data that is the database at query time.
In each case, once the dataset has been rendered as RDF (either dynamically or as a snapshot), it is identified in TopBraid by a URI (called its "base URI"). This base URI is important for identifying the dataset in the various data integration scenarios.
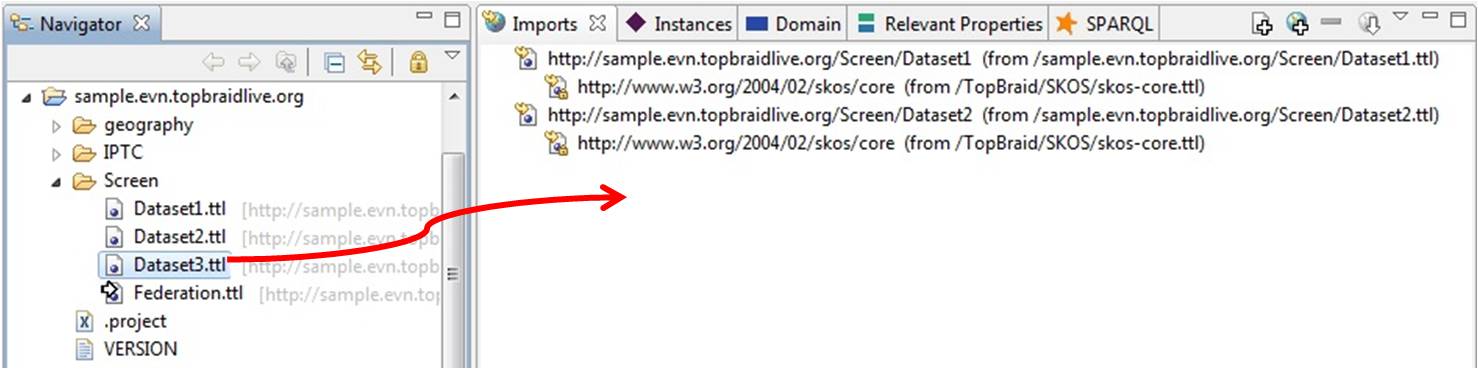
The simplest way to federate data in TopBraid Composer is to construct a model using OWL of the desired federation. This model uses owl:imports, and can be managed using the Imports View. Any number of datasets can be merged together simply by importing one into another. A typical scenario is to create a new dataset (in the form of a simple RDF file) and to import a number of other datasets into it by dragging and dropping them into the Imports view.
The result is a virtual federation of all datasets. All user interface views and SPARQL queries act on this federation of datasets.
Constructing data federations using the Imports View is the easiest way to do data integration, but does not provide a lot of control over how the data is to be integrated. TopBraid provides two other means of data integration that provide the user more control over the data to be integrated.
SPARQLMotion provides a scripting language for data management with fine-tuned control over what data is to be integrated. Data integration is achieved in a dataflow diagram. The diagram below shows the same simple data federation specified in the Imports View above, but done in SPARQLMotion.
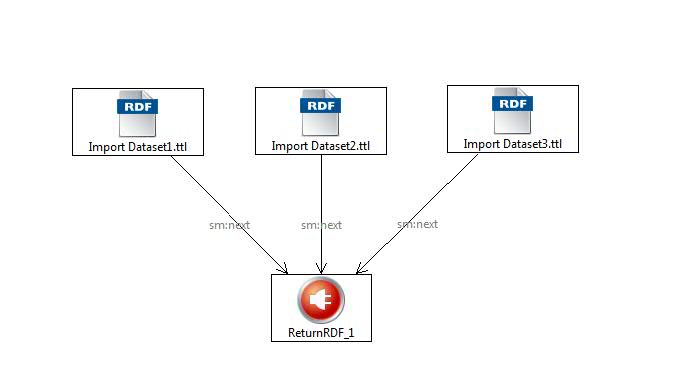
The same three datasets are combined in a dataflow to create an ad hoc federation.
Any of these datasets can be filtered using the Apply Construct module of SPARQLMotion. This module specifies that some transformation is to be applied to the input dataset. In a simple case, the various Apply Construct modules could filter triples out of each of the input datasets. In a more complex case, each Apply Construct module could recognize a particular pattern in each dataset, and the results of these matched patterns could be merged and proceeded further.
SPARQLMotion can be used to cascade such federations; transforming datasets, merging them, transforming them again, merging with other datasets, etc., to provide a sophisticated recipe for data federation.
SPARQL Web Pages is a text templating technology that makes it easy to build powerful and flexible web applications that interact with RDF data. Because SWP applications can use SPARQLMotion modules to retrieve data from a variety of sources, an SWP script can provide the framework for data integration processes.
Another approach to RDF-based data federation is through the query language SPARQL. SPARQL 1.1 provides a capability for querying multiple data sources in a single query, using the GRAPH and SERVICE keywords for named graphs in a data store and SPARQL endpoints, respectively.
SELECT ?rel
WHERE {
GRAPH <http://sample.evn.topbraidlive.org/Screen/Dataset1>
{?x a skos:Concept; skos:prefLabel ?label .}
GRAPH <http://sample.evn.topbraidlive.org/Screen/Dataset2>
{?y rdfs:label ?label .}
GRAPH <http://sample.evn.topbraidlive.org/Screen/Dataset3>
{?y skos:related ?rel }
}
Each dataset in the TopBraid workspace is available to a SPARQL query as a named graph (that is, referenceable via the GRAPH keyword in SPARQL 1.1), where the name of the graph is its base URI. The original source of the data is not important; relational databases, spreadsheets and RDF datasets are all treated equally as named graphs.
Similarly, external datasets that are published as SPARQL endpoints are available using the SERVICE keyword. The SERVICE and GRAPH keywords are both available in the same query:
SELECT ?concept ?item
WHERE {
GRAPH <http://sample.evn.topbraidlive.org/Screen/Dataset1>
{?concept a skos:Concept; skos:prefLabel ?label .}
SERVICE <http://dbpedia.org/sparql>
{?item rdfs:label ?label }
}
These methods are typically combined in a data integration solution using TopBraid; static structures of related data are specified as Imports, SPARQLMotion is used to coordinate detailed connections between datasets, and judicious use of the GRAPH and SERVICE keywords provide access to multiple local datasets (GRAPH) as well as remote data (SERVICE).